Qihep script: Difference between revisions
No edit summary |
|||
| (18 intermediate revisions by the same user not shown) | |||
| Line 1: | Line 1: | ||
{{main|Qihep}} | {{main|Qihep}} | ||
The '''Qihep script''' is the writing system used to write the Qihep language. | The '''Qihep script''' is the writing system used to write in the Qihep language. | ||
==Description== | ==Description== | ||
Qihep is written with a partially '''logographic''' script. It means that every syllable is written with a character, which is a little drawing, often somehow related to the meaning of the word it represents. The script is ''partially'' logographic, since many characters have lost their apparent relation to the meaning and are simple drawings. Every character gives no information about the phonetic nature of the syllable it represents. | Qihep is written with a partially '''logographic''' script. It means that every syllable is written with a character, which is a little drawing, often somehow related to the meaning of the word it represents. The script is ''partially'' logographic, since many characters have lost their apparent relation to the meaning and are simple drawings. Every character gives no information about the phonetic nature of the syllable it represents. | ||
| Line 7: | Line 7: | ||
:'''Tȳn ta kāǵ fa tȳn dōm bim fa vol ā''' | :'''Tȳn ta kāǵ fa tȳn dōm bim fa vol ā''' | ||
:''He said he wants to go home'' | :''He said he wants to go home'' | ||
Characters can be used for their phonetic value, usually to express foreign names or proper names which have no logographic representation. In this case they are marked by <u>underline</u>. | Characters can be used for their phonetic value, usually to express foreign names or proper names which have no logographic representation. In this case they are marked by <u>underline</u>. | ||
| Line 19: | Line 15: | ||
Underlined characters are thus read for their sound, with no attention for the meaning of the syllable. | Underlined characters are thus read for their sound, with no attention for the meaning of the syllable. | ||
===Space and punctuation=== | |||
Words are not written separately nor sentences are. Only sentences can be separated by the space of a character, when there is a pause in the speech or when the two sentences are clearly distinct in meaning. | |||
The space between the characters is usually the same, compounds syllables are not written closer than the other ones, even if the word is perceived as a compound. | |||
Due to its logographic nature, Qihep script makes a very limited use of punctuation. There is no equivalent for a comma, a full stop, a semicolon, and so on. | |||
Some soundless characters are used, however, with the role of punctuation marks: | |||
A soundless character is usually inserted at the end of an entire speech period, when it is perceived that this period has reached to a defined end in meaning. Usually the next period has something clearly new to express. | |||
Direct speech is written between two soundless characters, that are comparable to our inverted commas. | Direct speech is written between two soundless characters, that are comparable to our inverted commas. | ||
| Line 43: | Line 50: | ||
The transcription preserves the Qihep use of <u>underline</u>, when a word is written with logograms, which are used for their sound and not for their meaning: | The transcription preserves the Qihep use of <u>underline</u>, when a word is written with logograms, which are used for their sound and not for their meaning: | ||
:[[File:Qihep example 4.png|140px]] | |||
:'''Ul <u>Rōma</u> fut bim fa vol''' | |||
:''I am going to go to Rome'' | |||
For educational purpose in books, transcribed compounded words can be shown with their syllables separated by a dot, '''∙''', to avoid confusion in students, who may not recognize the syllable boundary. | |||
:[[File:Qihep example 2.png|215px]] | |||
:'''Xūc∙kreś∙mor <u>Do∙ic∙lān</u> fut bim fa vol nah''' | |||
:''I was told the teacher is going to go to Germany'' | |||
This is usually called the ''educational syllabicated transcription''. | |||
Examples in this grammar are usually given only in transcribed form. | Examples in this grammar are usually given only in transcribed form. | ||
===Cyrillic transcription=== | |||
A system was also devised to easily transcribe Qihep using the Cyrillic script. This kind of transcription is based on the phonemes of the language too, with no regard for the nature of the characters used in the logographic script. | |||
This is the trascription used: | |||
{| | |||
!''Letter'' || а || а̄ || б || в || г || д || е || е̄ || ж || и || ӣ || ј || к || ҡ || л || м || н || њ || о || ō || п || р || с || т || у || ӯ || ў || ф || х || һ || ц || ч || ш || ы || ы̄ | |||
|- | |||
|'''IPA value''' || {{IPA|[a]}} || {{IPA|[aː]}} || {{IPA|[b]}} || {{IPA|[v]}} || {{IPA|[g]}} || {{IPA|[d]}} || {{IPA|[e]}} || {{IPA|[eː]}} || {{IPA|[ʤ]}}|| {{IPA|[i]}} || {{IPA|[iː]}} || {{IPA|[j]}} || {{IPA|[k]}} || {{IPA|[kʷ]}} || {{IPA|[l]}} || {{IPA|[m]}} || {{IPA|[n]}} || {{IPA|[ɲ]}}|| {{IPA|[o]}} || {{IPA|[oː]}} || {{IPA|[p]}} || {{IPA|[r]}} || {{IPA|[s]}} || {{IPA|[t]}} || {{IPA|[u]}} || {{IPA|[uː]}} || {{IPA|[w]}} || {{IPA|[f]}} || {{IPA|[x]}} || {{IPA|[h]}} || {{IPA|[ʦ]}}|| {{IPA|[ʧ]}} || {{IPA|[ʃ]}} || {{IPA|[ə]}} || {{IPA|[əː]}} || | |||
|} | |||
The rules used are the same as for the Latin trascription: | |||
:[[File:Qihep example 1.png|215px]] | |||
:'''Ты̄н та ка̄ж фа ты̄н дōм бим фа вол а̄''' | |||
:''He said he wants to go home'' | |||
:'''Ул <u>Маскыва</u> бим фа неч''' | |||
:''I must go to Moscow'' | |||
The Cyrillic transcription is a possibility, but it will never be used again in this grammar. | |||
[[Category:Qihep|Script]] | [[Category:Qihep|Script]] | ||
Latest revision as of 09:21, 2 November 2020
- Main article: Qihep
The Qihep script is the writing system used to write in the Qihep language.
Description
Qihep is written with a partially logographic script. It means that every syllable is written with a character, which is a little drawing, often somehow related to the meaning of the word it represents. The script is partially logographic, since many characters have lost their apparent relation to the meaning and are simple drawings. Every character gives no information about the phonetic nature of the syllable it represents.

- Tȳn ta kāǵ fa tȳn dōm bim fa vol ā
- He said he wants to go home
Characters can be used for their phonetic value, usually to express foreign names or proper names which have no logographic representation. In this case they are marked by underline.

- Xūckreśmor Doiclān fut bim fa vol nah
- I was told the teacher is going to go to Germany
Underlined characters are thus read for their sound, with no attention for the meaning of the syllable.
Space and punctuation
Words are not written separately nor sentences are. Only sentences can be separated by the space of a character, when there is a pause in the speech or when the two sentences are clearly distinct in meaning.
The space between the characters is usually the same, compounds syllables are not written closer than the other ones, even if the word is perceived as a compound.
Due to its logographic nature, Qihep script makes a very limited use of punctuation. There is no equivalent for a comma, a full stop, a semicolon, and so on.
Some soundless characters are used, however, with the role of punctuation marks:
A soundless character is usually inserted at the end of an entire speech period, when it is perceived that this period has reached to a defined end in meaning. Usually the next period has something clearly new to express.
Direct speech is written between two soundless characters, that are comparable to our inverted commas.
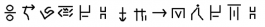
- Ī rȳs rā kāǵ fa "Ma la tykmeś qin fa si"
- and she said: "Come here!"
Transcription
Qihep can be easily transcribed using the Latin script. Trascription is based on the phonemes of the languages with no regard for the nature of the characters used in the logographic script.
This is the trascription used:
| Letter | a | ā | b | c | d | e | ē | f | g | ǵ | h | i | ī | j | k | l | m | n | ń | o | ō | p | q | r | s | ś | t | ts | u | ū | v | w | x | y | ȳ | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| IPA value | [a] | [aː] | [b] | [ʧ] | [d] | [e] | [eː] | [f] | [g] | [ʤ] | [h] | [i] | [iː] | [j] | [k] | [l] | [m] | [n] | [ɲ] | [o] | [oː] | [p] | [kʷ] | [r] | [s] | [ʃ] | [t] | [ʦ] | [u] | [uː] | [v] | [w] | [x] | [ə] | [əː] |
The macron ¯ above letters marks long vowels. The letter q represents the labialized velar stop [kʷ], which is perceived as a single phoneme and thus transcribed. The affricate phoneme [ʦ] is perceived as a single sound, but as it counts as two regarding the syllabic structure, it is transcribed with two letters ts to remember its phomenic weight.
Differently from the rules of the logographic script, in the transcription words are separated according to their meaning. Compound words are thus written together to facilitate comprehension. Capitalization is optional, since it has no meaning in a logographic script. Transcribed words are usually capitalized at the beginning of a new paragraph or when expressing a proper name to facilitate comprehension.
The transcription preserves the Qihep use of underline, when a word is written with logograms, which are used for their sound and not for their meaning:

- Ul Rōma fut bim fa vol
- I am going to go to Rome
For educational purpose in books, transcribed compounded words can be shown with their syllables separated by a dot, ∙, to avoid confusion in students, who may not recognize the syllable boundary.
- Xūc∙kreś∙mor Do∙ic∙lān fut bim fa vol nah
- I was told the teacher is going to go to Germany
This is usually called the educational syllabicated transcription.
Examples in this grammar are usually given only in transcribed form.
Cyrillic transcription
A system was also devised to easily transcribe Qihep using the Cyrillic script. This kind of transcription is based on the phonemes of the language too, with no regard for the nature of the characters used in the logographic script.
This is the trascription used:
| Letter | а | а̄ | б | в | г | д | е | е̄ | ж | и | ӣ | ј | к | ҡ | л | м | н | њ | о | ō | п | р | с | т | у | ӯ | ў | ф | х | һ | ц | ч | ш | ы | ы̄ | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| IPA value | [a] | [aː] | [b] | [v] | [g] | [d] | [e] | [eː] | [ʤ] | [i] | [iː] | [j] | [k] | [kʷ] | [l] | [m] | [n] | [ɲ] | [o] | [oː] | [p] | [r] | [s] | [t] | [u] | [uː] | [w] | [f] | [x] | [h] | [ʦ] | [ʧ] | [ʃ] | [ə] | [əː] |
The rules used are the same as for the Latin trascription:
- Ты̄н та ка̄ж фа ты̄н дōм бим фа вол а̄
- He said he wants to go home
- Ул Маскыва бим фа неч
- I must go to Moscow
The Cyrillic transcription is a possibility, but it will never be used again in this grammar.