Vingdagese: Difference between revisions
m (→Consonants) |
|||
| (49 intermediate revisions by the same user not shown) | |||
| Line 1: | Line 1: | ||
__NOTOC__ | __NOTOC__ | ||
{{SCBar|name=Vưng-Ḍác Tǫ|#Grammar{{!}}Grammar|/Lexicon{{!}}Lexicon|#Writing & Script{{!}}Writing & Script|:Category:Vingdagese Images{{!}}''Image Category''|:Category:Vingdagese Characters{{!}}''Character Category''|:Category:Vingdagese Phonograms{{!}}''Phonogram Category''}} | |||
{{SCBar|name=Vưng-Ḍác Tǫ|#Grammar{{!}}Grammar|/Lexicon{{!}}Lexicon| | |||
{{/Infobox}} | {{/Infobox}} | ||
== Phonology == | == Phonology == | ||
'''Vưng-Ḍác Tǫ''' ({{VDT|ving|12px}}{{VDT|daac|12px}}{{VDT| | '''Vưng-Ḍác Tǫ''' ({{VDT|ving|12px}}{{VDT|daac|12px}}{{VDT|to^|12px}}) has 17 distinct consonants in its inventory (with a bit of allophony) and has 15 vowel phonemes. The vowel space is divided into 3 groups, namely: the a-group, i-group, and the o-group. This gives '''Vưng-Ḍác Tǫ''' a rather large range of possible syllables despite the fact that clusters are limited and most words are only one syllable in length with a smattering of two syllable compounds. | ||
=== Consonants === | === Consonants === | ||
| Line 20: | Line 19: | ||
|- | |- | ||
! colspan="2" | Plosive | ! colspan="2" | Plosive | ||
| '''p''' /p/ ~ [b] || '''t''' /t/ ~ [d] || '''c''' /k/ ~ [ | | '''p''' /p/ ~ [b] || '''t''' /t/ ~ [d] || '''c''' ('''q''') /k/ ~ [ɡ; q] || '''Ø''' ('''’'''; '''q''') /ʔ/ ~ [q] | ||
|- | |- | ||
! colspan="2" | Implosive | ! colspan="2" | Implosive | ||
| Line 26: | Line 25: | ||
|- | |- | ||
! colspan="2" | Fricative | ! colspan="2" | Fricative | ||
| '''v''' /v/ ~ [w] || '''dh''' (''' | | '''v''' ('''w''') /v/ ~ [w] || '''dh''' /ð/ || '''j''' ('''gh'''; '''g''') /ʝ/ ~ [ɣ; ɡ] || | ||
|- | |- | ||
! colspan="2" | Rhotic | ! colspan="2" | Rhotic | ||
| Line 38: | Line 37: | ||
|- | |- | ||
! width="125px" | A-Group | ! width="125px" | A-Group | ||
| '''a''' /a/ || '''e''' /ɛ/ || '''á''' ('''aa''') /aː/ || '''ą''' /ã/ || '''ay''' /aɪ̯/ | | '''a''' /a/ || '''e''' /ɛ/ ~ [ə] || '''á''' ('''aa''') /aː/ || '''ą''' /ã/ || '''ay''' /aɪ̯/ | ||
|- | |- | ||
! I-Group | ! I-Group | ||
| '''i''' /i/ || '''ư''' /ɪ/ || '''é''' ('''ee''') /eː/ || '''į''' /ĩ/ || | | '''i''' /i/ || '''ư''' /ɪ/ || '''é''' ('''ee''') /eː/ || '''į''' /ĩ/ || '''ya''' /ɪə̯/ ~ [iː] | ||
|- | |- | ||
! O-Group | ! O-Group | ||
| Line 48: | Line 47: | ||
=== Phonotactics === | === Phonotactics === | ||
The general description of the syllable unit in '''Vưng-Ḍác Tǫ''' is the following: | The general description of the syllable unit in '''Vưng-Ḍác Tǫ''' is the following: C(r, w)V(P, N, F). There are, of course, some provisos that go along with that generic description. Many of the constraints and other changes to that basic structure are described in the following section on [[#Allophony|allophony]]. | ||
=== Allophony === | === Allophony === | ||
Some general allophonic rules (as well as mentions of orhography in the romanization): | Some general allophonic rules (as well as mentions of orhography in the romanization): | ||
* If /k/ appears in a syllable directly before a vowel belonging to the o-group, it becomes | * If /k/ appears in a syllable directly before a vowel belonging to the o-group, it becomes [q] (and is written as such; this process is blocked by an intervening consonant). | ||
* If a glottal stop ends a syllable, it becomes | * If a glottal stop ends a syllable, it becomes [q] and is written as such. | ||
**Therefore, if a syllable ends in '''q''' it came from a glottal stop, however if it begins a syllable it came from /k/. | **Therefore, if a syllable ends in '''q''' it came from a glottal stop, however if it begins a syllable it came from /k/. | ||
* Long nasal consonants cannot form clusters, nor can they occur in the coda of a syllable. | * Long nasal consonants cannot form clusters, nor can they occur in the coda of a syllable. | ||
* | * Neither implosive consonants nor the glottal stop can form consonant clusters. | ||
* When initial, the rhotic is trilled, when it appears in consonant clusters it is tapped. | * When initial, the rhotic is trilled, when it appears in consonant clusters it is tapped. | ||
* If a vowel would begin a syllable, it instead begins with | * The consonant /ʝ/ has a good amount of allophony associated with it (each with requisite spelling changes in the Romanization): | ||
** When it appears as a final, it moves to a velar realization, namely: [ɣ]. | |||
** As an initial and followed by /ɾ/ it undergoes fortition to [ɡɾ]. | |||
** However, if followed by /w/ it instead, becomes [ɡw]. | |||
* If a vowel would begin a syllable, it instead begins with [ʔ], which is unwritten. | |||
* When /ɛ/ is in the final position of a syllable, it centralizes to a shcwa: [ə]. | |||
* If a glottal stop begins the second syllable in a two syllable compound, the consonant is written as an apostrophe. | * If a glottal stop begins the second syllable in a two syllable compound, the consonant is written as an apostrophe. | ||
* Stops that appear in the coda of a syllable are voiced, however the spelling isn't changed (the /ʔ/ → /q/ situation being an exception). | * Stops that appear in the coda of a syllable are voiced, however the spelling isn't changed (the /ʔ/ → /q/ situation being an exception). | ||
* The o-group's diphthong's two realizations are in free variation and depend on the speaker. | * The o-group's diphthong's two realizations are in free variation and depend on the speaker. | ||
* Some speakers pronounce the i-group diphthong ('''ya''') as [iː] rather than [ɪə̯]. The two are not conditioned variants and are in free variation. | |||
Another allophonic variation occurs in two-syllable compound words (such as the language's name). Whenever an implosive appears second in one of these two-syllable compounds, it laxes the vowel in the first position of the compound if it is a plain vowel and de-lengthens a long vowel to its plain equivalent. | Another allophonic variation occurs in two-syllable compound words (such as the language's name). Whenever an implosive appears second in one of these two-syllable compounds, it laxes the vowel in the first position of the compound if it is a plain vowel and de-lengthens a long vowel to its plain equivalent. | ||
== Grammar == | == Grammar == | ||
Vingdagese has a rather simple grammar in which there are few exceptions to rules, and essentially no morphology. Instead, it uses particles, and noun- and verb- compounding to express more complex structures. Possession is somewhat of an exception in that there are two methods to express it, with one only being used if the animacy hierarchy must be violated. Vingdagese, as the previous statement would imply, also has a hierarchy with regard to animacy. This means an obviative particle exists to de-rank nouns, as well as a direct-inverse structure to its clauses. | |||
Another feature of the language is the use of a small system of noun classifiers when a number of demonstrative is used with a noun. These also come into play as a form of noun replacement when a noun has already been referred to an exchange. This enables a sort of verbal shorthand to be used. | |||
=== Pronouns === | === Pronouns === | ||
| Line 84: | Line 91: | ||
|- | |- | ||
! colspan="2" | Second | ! colspan="2" | Second | ||
| {{VDT|rej}}<br>''' | | {{VDT|rej}}<br>'''regh'''<br>''you'' || colspan="2" | {{VDT|duu}}<br>'''ḍú'''<br>''you (few, two)'' || {{VDT|dhi}}<br>'''dhi'''<br>''you (<u>{{sc|pl}}</u>)'' | ||
|- | |- | ||
! colspan="2" | Third | ! colspan="2" | Third | ||
| {{VDT|dhu'n}}<br>'''dhưn'''<br>''he; she; they (<u>{{sc|sg}}</u>)'' || colspan="3" | {{VDT|dhrej}}<br>''' | | {{VDT|dhu'n}}<br>'''dhưn'''<br>''he; she; they (<u>{{sc|sg}}</u>)'' || colspan="3" | {{VDT|dhrej}}<br>'''dhregh'''<br>''they (few, <u>{{sc|pl}}</u>)'' | ||
|} | |} | ||
| Line 94: | Line 101: | ||
Each classifier is used as a suffix to the noun to which it refers. In some cases, this will trigger vowel laxing/shortening since a number of classifiers contain an implossive consonant. This system is much smaller than some East Asian languages' classifier (measure word) systems, and is more in line in number of items with European noun class systems. | Each classifier is used as a suffix to the noun to which it refers. In some cases, this will trigger vowel laxing/shortening since a number of classifiers contain an implossive consonant. This system is much smaller than some East Asian languages' classifier (measure word) systems, and is more in line in number of items with European noun class systems. | ||
All humans and anthropomorphized animals belong to the human class. Using a non-human classifier in reference to a person is extreme sign of disrespect or possibly disregard for that person entirely (depending on what class is chosen). All non-antrhopomorphized animals fall into the animate class. However, this class is also for things that routinely move of their own accord including rain, lakes, fire, fields of tall grass, etc. Non-animate nouns can be referred to as part of that class if something about them makes movement important. A thrown ball, for instance might be referred to that way at times. The tall class is fairly restricted. This class is for any object that is much taller or longer than it is wide. Objects such as trees, rivers, poles, mountains, deep cracks and other similar geographic features all fall into this category. However, there aren't many cases where this category is extended. The "round" classifier is perhaps the most open. Any object that isn't considered to be tall, shapeless, especially flat or alive can end up in this category. As such, the round classifier is the one most common to be generalized similarly to the Chinese classifier '''個''' ('''gè'''). Next is the flat classifier. This one is used mainly for things like tables, boards, plains, the surface of a calm lake, etc. It too is a rather restrictive class. Amorphous is the classifier that is applied to pools of water like puddles, types of liquids (esp. foods), bodily fluids, etc. And last but not least, is the category associated with every other noun that does not have a physical existence per se, this class is for ideas, thoughts, emotions, states of being, etc. | |||
{| class="wikitable" style="text-align: center;" | {| class="wikitable" style="text-align: center;" | ||
! style="vertical-align: bottom;" colspan="6" | Physical !! style="vertical-align: bottom;" rowspan="3" width="64px" | | ! style="vertical-align: bottom;" colspan="6" | Physical !! style="vertical-align: bottom;" rowspan="3" width="64px" | Abstract | ||
|- | |- | ||
! style="vertical-align: bottom;" rowspan="2" width="64px" | Human !! style="vertical-align: bottom;" rowspan="2" width="64px" | Animate !! style="vertical-align: bottom;" colspan="4" width="64px" | Inanimate | ! style="vertical-align: bottom;" rowspan="2" width="64px" | Human !! style="vertical-align: bottom;" rowspan="2" width="64px" | Animate !! style="vertical-align: bottom;" colspan="4" width="64px" | Inanimate | ||
| Line 105: | Line 114: | ||
|} | |} | ||
* <b>Ḅo</b>'s phonogram, when used as a clasifier, is not the traditional symbol with an open bottom, but instead a version of it using a closed rectangle instead. This may have become common practice to make it less similar to the long-object classifier and/or animate classifier. | * <b>Ḅo</b>'s phonogram, when used as a clasifier, is not the traditional symbol with an open bottom, but instead a version of it using a closed rectangle instead. This may have become common practice to make it less similar to the long-object classifier and/or animate classifier. | ||
* As more nouns are coined, it may become necessary to revise the names/uses of these categories somewhat. At present, it seems like an okay system that should be able to handle itself. Other terms for the overarching categories may eventually be coined so that perhaps a generic "inanimate" classifier can be used. However, I don't believe that would be useful as it should simply be sorted into one of the sub-divisions. | |||
=== Animacy Hierarchy === | === Animacy Hierarchy === | ||
Related to classifiers, and the above chart, is the animacy hierarchy. Things can be "owned" only by those things farther left on the chart than them. So, what this means is that a thought ( | Related to classifiers, and the above chart, is the animacy hierarchy. Things can be "owned" only by those things farther left on the chart than them. So, what this means is that a thought (abstract) can't own anything through use of the {{sc|poss}} suffix, however, anything else classed on the table can own it. What this means is that should something flat need to own something round an alternate construction would need to be used to indicate that. Typically this construction will use a verb indicating possession along with the <u>{{sc|inv}}</u>erse marker ('''ḍưm''' {{VDT|P-du'm|6px}}). | ||
The above hierarchy is followed also for transitive verbs. It is always assumed that an object/person higher on the hierarchy will perform the action on the object lower on the hierarchy. This is considered the direct construction. However, if the opposite is true, then the inverse marker must be appended to the verb to indicate that the hierarchy is working in reverse and the lower object is indeed the one performing the action. Should two participants in a transitive construction belong to the same rank on the hierarchy, then the object to which the action is occurring is "de-ranked" on the hierarchy by appending the <u>{{sc|obv}}</u>iative particle phonogram | The above hierarchy is followed also for transitive verbs. It is always assumed that an object/person higher on the hierarchy will perform the action on the object lower on the hierarchy. This is considered the direct construction. However, if the opposite is true, then the inverse marker must be appended to the verb to indicate that the hierarchy is working in reverse and the lower object is indeed the one performing the action. Should two participants in a transitive construction belong to the same rank on the hierarchy, then the object to which the action is occurring is "de-ranked" on the hierarchy by appending the <u>{{sc|obv}}</u>iative particle phonogram, namely, '''ti''' ({{VDT|P-ti|6px}}). | ||
As subcategories of the "human" rank in the hierarchy, the pronouns are ranked second, first, third. Additionally, a singular object always ranks higher than a plural object. | As subcategories of the "human" rank in the hierarchy, the pronouns are ranked second, first, third. Additionally, a singular object always ranks higher than a plural object. | ||
Given the above, the full hierarchy is as follows: | Given the above, the full hierarchy is as follows: | ||
{| class="wikitable" style="text-align: center;" | {| class="wikitable" style="text-align: center;" width="40%" | ||
! colspan="3" | Human | ! colspan="3" | Human | ||
| rowspan="2" width="11%" | Animate | |||
! colspan="4" width="11%" | Inanimate | |||
| rowspan="2" | Abstract | |||
|- | |- | ||
| width="11%" | Second || width="11%x" | First || width="11%" | Third || width="11%" | Long || width="11%" | Round || width="11%" | Flat || width="11%" | Amorphous | |||
|} | |} | ||
{| class="wikitable" style="text-align: center;" | {| class="wikitable" style="text-align: center;" width="40%" | ||
! width="50%" | Singular || width="50%" | Plural | |||
|} | |} | ||
| Line 127: | Line 140: | ||
In addition to the aspects described below in the table, a verb bereft of any of the aspectual markers is considered to be in a type of general '''gnomic''' aspect; that is, stating the nature of things, or without any sense of time or the relation of the action to the passage of time or manner. | In addition to the aspects described below in the table, a verb bereft of any of the aspectual markers is considered to be in a type of general '''gnomic''' aspect; that is, stating the nature of things, or without any sense of time or the relation of the action to the passage of time or manner. | ||
Each aspect exists in opposition to another aspect, with the exception of the Frequentative. These dualities usually focus on a particular quality that unites them, but also divides their usages. They are laid out along with their "opposite" in the table below. | |||
{| class="wikitable" style="text-align: center;" | {| class="wikitable" style="text-align: center;" | ||
! width=" | ! width="160x" height="32px" | Perfective | ||
| width="64px" rowspan="2" | {{VDT|P- | | width="64px" rowspan="2" | {{VDT+|P-a|-’a|16px}} | ||
! width="160x" | Imperfective | |||
| width="64px" rowspan="2" | {{VDT|P-ga|16px}}<br>'''-ġa''' | |||
|- | |- | ||
| ''Action is completed.'' | | height="32px" | ''Action is completed (as expected).'' || ''Action is continuous.'' | ||
|- | |- | ||
! | ! height="32px" | Inchoative | ||
| rowspan="2" | {{VDT|P- | | rowspan="2" height="32px" | {{VDT+|P-na|-na|16px}} | ||
! Cessative | |||
| rowspan="2" | {{VDT+|P-go|-ġo|16px}} | |||
|- | |- | ||
| | | height="32px" | ''Action is about to start, or just started.'' || ''Action has just ended, or was interrupted.'' | ||
| ''Action is | |||
| | |||
| ''Action just | |||
|- | |- | ||
! height="32px" | Progressive | |||
| rowspan="2" height="32px" | {{VDT+|P-no|-no|16px}} | |||
! Momentane | ! Momentane | ||
| rowspan="2" | {{VDT|P-dho| | | rowspan="2" | {{VDT+|P-dho|-dho|16px}} | ||
|- | |- | ||
| ''Action | | height="32px" | ''Action is on-going (toward completion).'' || ''Action occurs once, over a negligible time.'' | ||
|- | |- | ||
! | ! height="32px" | Frequentative | ||
| rowspan="2" | {{VDT|P- | | rowspan="2" height="32px" | {{VDT+|P-2x|<u>{{sc|Redupl}}</u>|16px}} | ||
|- | |- | ||
| '' | | height="32px" | ''Action occurs many times; often.'' | ||
|} | |} | ||
There is also an emphatic particle that is related to, but not mutually exclusive with, any of the above aspects that marks explicit and often forceful intention of the action that it modifies. This marker is '''ḅi''' ({{VDT|P-bi|6px}}). | |||
==== Perfective vs. Imperfective ==== | |||
The duality here is whether the action is completed (or even complete-''able'' in the first place). An action in the perfective aspect is one with a natural end-point and has reached that logical endpoint. On the other hand, actions in the imperfective express either that there is no natural endpoint for that action, or that such an endpoint is not going to be reached. Actions such as "going for a walk" are actions that are imperfective as there is no normal endpoint until the person stops walking. | |||
==== Inchoative vs. Cessative ==== | |||
Here the central focus is on the beginning and end of an action. Where the perfective expresses an action that ended as expected, the Cessative is used most often when an action is stopped abrubtly, especially with actions that do have a natural endpoint that simply hasn't been reached due to interruption. Inchoative aspect is used to express the nature of "about to..." or "has just begun to..." No sense of premature beginning is implied, contrary to the other half of this pair. | |||
==== Progressive vs. Momentane ==== | |||
This duality centers around the nature of the action's completion with relation to its endpoint. A progressive action is one in which the action moves more and more toward completion the longer it is performed. Painting (esp. a discrete object) is a good example of a time to use the progressive. However, the momentane aspect is used when the entirety of the action is its own completion. Striking a bell, or punching a wall would both be momentane, as the entirety of the action is accomplished before any sense of progress could be ascertained. | |||
==== Frequentative ==== | |||
This is the only aspect without a partner, and the only aspect that is expressed as a changing suffix. Reduplication is used here to express the on-going nature of the event. Something in the frequentative happens over and over and over. Habitual actions could be described this way, as well as performing the same action continuously, one right after the next. This is distinguished from the progressive as no notable progress is made toward a foreseeable goal or endpoint. Hitting someone again and again and again could be frequentative; however, "hitting someone until they are unconscious," may be a better fit for the progressive aspect as there is a goal and natural endpoint of the action. | |||
=== Examples === | === Examples === | ||
In the following, <u>{{sc|intf}}</u> signifies an "intensifier" which makes what it modifies more impactful | In the following, <u>{{sc|intf}}</u> signifies an "intensifier" which makes what it modifies more impactful. | ||
{{VDT|duuj|24px}}{{VDT|P-ca|12px}}{{VDT| | {{VDT|duuj|24px}}{{VDT|P-ca|12px}}{{VDT|to^|24px}}{{VDT|P-2x|12px}}{{VDT|P-ga|12px}}{{VDT|cwo'c|24px}}{{VDT|ni|24px}}{{VDT|pra^|24px}}{{VDT|tre|24px}}{{VDT|cwo'c|24px}}{{VDT|3Dots|12px}} | ||
{{gl| | {{gl|Ḍúgh-ca|'''/''' ɗuːʝ.ka|ḍúgh-ca|{{sc|neg}}-{{sc|intf}}}} | ||
{{gl|tǫtǫ-ġa|tõ.tõ.ɠa|tǫ~ | {{gl|tǫtǫ-ġa|tõ.tõ.ɠa|tǫ~{{sc|redupl}}-ġa|to speak~{{sc|freq}}-{{sc|imp}}}} | ||
{{gl|cwơc|kwɔɡ|cwơc|1SG}} | {{gl|cwơc|kwɔɡ|cwơc|1SG}} | ||
{{gl|ni|ni|ni|or}} | {{gl|ni|ni|ni|or}} | ||
| Line 186: | Line 197: | ||
{{glend|Don't (keep) speak(ing) to me or my son (again)!}} | {{glend|Don't (keep) speak(ing) to me or my son (again)!}} | ||
{{VDT|cwo'c|24px}}{{VDT|eem|24px}}{{VDT|P- | {{VDT|cwo'c|24px}}{{VDT|eem|24px}}{{VDT|P-ca|12px}}{{VDT|P-vuu|12px}}{{VDT|pwo'|24px}}{{VDT|P-qo|12px}}{{VDT|3Dots|12px}} | ||
{{gl|Cwơc|'''/''' kwɔɡ|cwơc|1SG}} | {{gl|Cwơc|'''/''' kwɔɡ|cwơc|1SG}} | ||
{{gl| | {{gl|ém-ca|eːm.ca|ém-ca|to see-{{sc|intf}}}} | ||
{{gl|vú|vuː|vú|five}} | {{gl|vú|vuː|vú|five}} | ||
{{gl|pwơqo.|pwɔ.qo '''/'''|pwơ-qo|wolf-{{sc|clf.anim}}}} | {{gl|pwơqo.|pwɔ.qo '''/'''|pwơ-qo|wolf-{{sc|clf.anim}}}} | ||
{{glend|I stare (am staring) at five wolves.}} | {{glend|I stare (am staring) at five wolves.}} | ||
== Script & Characters == | == Writing & Script == | ||
{{/ | Each character written in Vưng-Ḍác Tǫ consists of two components. The first element is the Logogram and it serves to differentiate characters that mean different things, refer to different parts of speech or to give a clue to the meaning of the word. Here, logogram is used loosely and simply felt like a good word to describe the purpose of that portion of a character. A complete list of the possible logograms used in Vưng-Ḍác Tǫ is not feasible as there isn't a discreet number of them, and they have the most variation among them. Also, some of the logograms are indeed identical in appearance (if not function) to the second part of Vingdagese written characters. The second in each is a Phonogram. Phonograms '''do''' belong to a finite group, that describe a portion of the basic syllables possible in Vingdagese. Keep in mind that phonograms represent an older, simpler, version of the possible compliments of syllables. They do '''not''' include any consonant clusters, final consonants, non-cardinal vowels or diphthongs. All of that phonological information is conveyed in the combination of the Phonogram and Logogram portions toghether. Phonograms alone are not sufficient for proper pronunciation. | ||
=== Phonograms === | |||
The primary function of phonograms in the written language of Vingdagese is to establish a general range of possible ways in which the character could be pronounced. At one time, the language was a syllabary and was written exclusively with these phonograms (though some of them have changed form since then). However, a vast array of homophones and ambiguity began to exist in the written language... especially as the spoken language changed to add more variety in the ways that syllables were constructed. As such, additional components were added to lower ambiguity in the usage of characters. From that point on, there were two parts to each character, and the relationship between written phonogram and spoken syllable have greatly diverged. This has primarily occurred with respect to the exact vowel used, initial clusters and in coda consonants. Now, though, it does serve as a useful tool to organize characters alphabetize and also to roughly group similar sounding characters together. | |||
{| class = "wikitable" style="text-align:center; border: none; background: none;" | |||
| style="border: none; background: none;" | | |||
! colspan="14" | Cardinal Consonant | |||
|- | |||
! width="64px" | Vowel !! width="24px" | ’ !! width="24px" | Ḅ !! width="24px" | C !! width="24px" | Ḍ !! width="24px" | Dh !! width="24px" | G̣ !! width="24px" | T !! width="24px" | M !! width="24px" | N !! width="24px" | Ng !! width="24px" | P !! width="24px" | R !! width="24px" | J !! width="24px" | V | |||
|- | |||
! A | |||
| {{VDT|P-a|16px}} || {{VDT|P-ba|16px}} || {{VDT|P-ca|16px}} || {{VDT|P-da|16px}} || {{VDT|P-dha|16px}} || {{VDT|P-ga|16px}} || {{VDT|P-ta|16px}} || {{VDT|P-ma|16px}} || {{VDT|P-na|16px}} || {{VDT|P-nga|16px}} || {{VDT|P-pa|16px}} || {{VDT|P-ra|16px}} || {{VDT|P-ja|16px}} || {{VDT|P-va|16px}} | |||
|- | |||
! I | |||
| {{VDT|P-i|16px}} || {{VDT|P-bi|16px}} || {{VDT|P-ci|16px}} || {{VDT|P-di|16px}} || {{VDT|P-dhi|16px}} || {{VDT|P-gi|16px}} || {{VDT|P-ti|16px}} || {{VDT|P-mi|16px}} || {{VDT|P-ni|16px}} || {{VDT|P-ngi|16px}} || {{VDT|P-pi|16px}} || {{VDT|P-ri|16px}} || {{VDT|P-ji|16px}} || {{VDT|P-vi|16px}} | |||
|- | |||
! O | |||
| {{VDT|P-o|16px}} || {{VDT|P-bo|16px}} || {{VDT|P-qo|16px}} || {{VDT|P-do|16px}} || {{VDT|P-dho|16px}} || {{VDT|P-go|16px}} || {{VDT|P-to|16px}} || {{VDT|P-mo|16px}} || {{VDT|P-no|16px}} || {{VDT|P-ngo|16px}} || {{VDT|P-po|16px}} || {{VDT|P-ro|16px}} || {{VDT|P-jo|16px}} || {{VDT|P-vo|16px}} | |||
|} | |||
=== Characters === | |||
:—''For a chart of characters in Vưng-Ḍác Tǫ including unique phonograms, see: [[/Characters|Characters]]'' | |||
=== Writing === | |||
For the most part, strokes in written Vingdagese are in a similar order as to what they would be in Chinese, or what is presumed to be the stroke order in written Tangut. However, there are some notable exceptions. One such exception is that of the "square" (three of which make up the phonogram '''ca'''). In Chinese, each square would be written with three strokes, starting with the left, then the top and right sides forming an L-like shape with an uptick on the tail and finishing it off with the bottom stroke. However, in Vingdagese, it is written with only two strokes (one for the left and bottom and the other for the top and rightmost sides, with the omission of any uptick on the rightmost stroke). | |||
Another notable feature is the fact that many of the grammatical components of the language are written with a single phonogram instead of an entire character. In those situations, a middle dot is used to substitute what would have been the rest of the character and also to highlight that it isn't a full two-sided character. This dot is omitted in casual or quick writing, but is visually distinctive in a more formal hand. | |||
=== Numbers === | |||
Numbers in Vingdagese can be written formally or informally. In the formal method, the phonogram is included in each character which increases the stroke count significantly. However, they can also be written in their "short" forms which correspond in number to the number of strokes that are in the glyph and include solely the base form of the logogram that appears in the formal version. It is far more common to see the numbers written in their short versions. However, this version also has some forms that are identical to certain phonograms, but are pronounced differently when used as a number. The following table shows the pronunciation, value, short and formal forms of each character. Also of note is that Vingdagese uses an octal counting system in which the numbers 1-7 are the only ones used, and the character for 8 is actually a shorthand for 10. Place value has been used with these numbers for a number of years now, instead of a more archaic system where it was more like Roman numerals and there were other glyphs that served for 64 (8²), 512 (8³), etc. In the following table, the first character shown below each number is the long form, and the second is the short form. | |||
Numbers are also grouped differently than in the standard Western Base 10 system. In the Western world, numbers are grouped by every three zeroes (or in other words, by the thousand). However, by the Ving, they are instead grouped by every two zeroes, or by the hundred. This means that one thousand (1,000) is spoken about as ten-hundred (10·00), etc. However, should there be a single digit that would be placed in the next grouping as in {{red*}}1·00·00, it would instead be written without the first separator as: 100·00. | |||
(This also may make it a bit easier to identify in which base a number is being expressed, as the middle dot will be used often with octal notation and Base 10 numbers will still feature the comma.) | |||
{| class = "wikitable" style="text-align:center;" | |||
! width="64px" colspan="2" | One (1) !! width="64px" colspan="2" | Two (2) !! width="64px" colspan="2" | Three (3) !! width="64px" colspan="2" | Four (4) !! width="64px" colspan="2" | Five (5) !! width="64px" colspan="2" | Six (6) !! width="64px" colspan="2" | Seven (7) !! width="64px" colspan="2" | Eight (10) | |||
|- | |||
| {{VDT|mo't}} || {{VDT|P-mo't|16px}} || {{VDT|ay}} || {{VDT|P-ay|16px}} || {{VDT|dhaang}} || {{VDT|P-dhaang|16px}} || {{VDT|bo'}} || {{VDT|P-bo'|16px}} || {{VDT|vuu}} || {{VDT|P-vuu|16px}} || {{VDT|nnem}} || {{VDT|P-nnem|16px}} || {{VDT|qo'}} || {{VDT|P-qo'|16px}} || {{VDT|bej}} || {{VDT|P-bej|16px}} | |||
|- | |||
| colspan="2" | '''mơt''' || colspan="2" | '''ay''' || colspan="2" | '''dháng''' || colspan="2" | '''ḅơ''' || colspan="2" | '''vú''' || colspan="2" | '''nnem''' || colspan="2" | '''qơ''' || colspan="2" | '''ḅegh''' | |||
|} | |||
{| class = "wikitable" style="text-align:center;" | |||
! width="64px" colspan="2" | Zero (0) !! width="64px" colspan="2" | 100 !! width="64px" colspan="2" | 10·00 !! width="64px" colspan="2" | 100·00 !! width="64px" colspan="2" | 10·00·00 !! width="64px" colspan="2" | 100·00·00 | |||
|- | |||
| {{VDT|ring}} || {{VDT|P-ring|16px}} || {{VDT|cren}} || {{VDT|P-cren|16px}} || {{VDT|twee}} || {{VDT|P-twee|16px}} || {{VDT|praq}} || {{VDT|P-praq|16px}} || {{VDT|gu'c}} || {{VDT|P-gu'c|16px}} || {{VDT|mmit}} || {{VDT|P-mmit|16px}} | |||
|- | |||
| colspan="2" | '''ring''' || colspan="2" | '''cren''' || colspan="2" | '''twé''' || colspan="2" | '''praq''' || colspan="2" | '''ġưc''' || colspan="2" | '''mmit''' | |||
|} | |||
==== Examples ==== | |||
Below are a few examples of the number system in actual use, as well as a comparison of the long and short forms in the final part separated by a slash. | |||
* 37 {{small|(Base 10)}} → 45 {{small|(Base 8)}} → {{VDT|P-bo'|6px}}{{VDT|P-vuu|6px}} → {{VDT|37|12px}} / {{VDT|bo'|12px}}{{VDT|vuu|12px}} | |||
** In this example, the resultant character has some elements combined to reduce strokes and redundancy. | |||
* 8,763 {{small|(Base 10)}} → 210·73 {{small|(Base 8)}} → {{VDT|P-ay|6px}}{{VDT|P-mo't|6px}}{{VDT|P-ring|6px}}{{VDT|1Dot|6px}}{{VDT|P-qo'|6px}}{{VDT|P-dhaang|6px}} / {{VDT|ay|12px}}{{VDT|mo't|12px}}{{VDT|ring|12px}}{{VDT|1Dot|6px}}{{VDT|qo'|12px}}{{VDT|dhaang|12px}} | |||
** Use of the full characters gets quite unwieldy with large numbers. As such, one does not tend to see it. | |||
* 4,097 {{small|(Base 10)}} → 100·01 {{small|(Base 8)}} → {{VDT|P-cren|6px}}{{VDT|1Dot|6px}}{{VDT|P-ring|6px}}{{VDT|P-mo't|6px}} or {{VDT|P-mo't|6px}}{{VDT|P-ring|6px}}{{VDT|P-ring|6px}}{{VDT|1Dot|6px}}{{VDT|P-ring|6px}}{{VDT|P-mo't|6px}} | |||
** In this example, the character '''cren''' is used to abbreviate a 1 with two 0s, since it had been used as 100 (or 64 in Base 10) in the older system. Now, these characters are only used as part of shorthand since they have been obsoleted by the advent of the current place value system. | |||
== Lexicon == | == Lexicon == | ||
:—''For | :—''For the current list of words in Vưng-Ḍác Tǫ, see: [[/Lexicon|Lexicon]].'' | ||
== Creator Comments== | == Creator Comments== | ||
Latest revision as of 00:14, 3 September 2020
 | |
|---|---|
| Vingdagese Vưng-Ḍác Tǫ | |
| Pronounced: | Native: /vɪŋ.ɗaːg tõ/ Anglicized: /vɪŋ.dəg.iːz/ |
| Timeline and Universe: | Alternate Earth |
| Species: | Human |
| Spoken: | Carnassus |
| Writing system: | "Logography" |
| Genealogy: | Language Isolate |
| Typology | |
| Morphological type: | Isolating |
| Morphosyntactic alignment: | Direct Inverse |
| Basic word order: | SVO; Head-Initial |
| Credits | |
| Creator: | Thrice Xandvii | ✎ |
| Created: | September 2017 |
Phonology
Vưng-Ḍác Tǫ (![]()
![]()
![]() ) has 17 distinct consonants in its inventory (with a bit of allophony) and has 15 vowel phonemes. The vowel space is divided into 3 groups, namely: the a-group, i-group, and the o-group. This gives Vưng-Ḍác Tǫ a rather large range of possible syllables despite the fact that clusters are limited and most words are only one syllable in length with a smattering of two syllable compounds.
) has 17 distinct consonants in its inventory (with a bit of allophony) and has 15 vowel phonemes. The vowel space is divided into 3 groups, namely: the a-group, i-group, and the o-group. This gives Vưng-Ḍác Tǫ a rather large range of possible syllables despite the fact that clusters are limited and most words are only one syllable in length with a smattering of two syllable compounds.
Consonants
| Labial | Coronal | Dorsal | Laryngeal | ||
|---|---|---|---|---|---|
| Nasal | Short | m /m/ | n /n/ | ng /ŋ/ | |
| Long | mm /mː/ | nn /nː/ | nng /ŋː/ | ||
| Plosive | p /p/ ~ [b] | t /t/ ~ [d] | c (q) /k/ ~ [ɡ; q] | Ø (’; q) /ʔ/ ~ [q] | |
| Implosive | ḅ /ɓ/ | ḍ /ɗ/ | ġ /ɠ/ | ||
| Fricative | v (w) /v/ ~ [w] | dh /ð/ | j (gh; g) /ʝ/ ~ [ɣ; ɡ] | ||
| Rhotic | r /r/ ~ [ɾ] | ||||
Vowels
| Plain | Lax | Long | Nasal | Diphthong | |
|---|---|---|---|---|---|
| A-Group | a /a/ | e /ɛ/ ~ [ə] | á (aa) /aː/ | ą /ã/ | ay /aɪ̯/ |
| I-Group | i /i/ | ư /ɪ/ | é (ee) /eː/ | į /ĩ/ | ya /ɪə̯/ ~ [iː] |
| O-Group | o /o/ | ơ /ɔ/ | ú (uu) /uː/ | ǫ /õ/ | oy /ɔɪ̯/ ~ [oɪ̯] |
Phonotactics
The general description of the syllable unit in Vưng-Ḍác Tǫ is the following: C(r, w)V(P, N, F). There are, of course, some provisos that go along with that generic description. Many of the constraints and other changes to that basic structure are described in the following section on allophony.
Allophony
Some general allophonic rules (as well as mentions of orhography in the romanization):
- If /k/ appears in a syllable directly before a vowel belonging to the o-group, it becomes [q] (and is written as such; this process is blocked by an intervening consonant).
- If a glottal stop ends a syllable, it becomes [q] and is written as such.
- Therefore, if a syllable ends in q it came from a glottal stop, however if it begins a syllable it came from /k/.
- Long nasal consonants cannot form clusters, nor can they occur in the coda of a syllable.
- Neither implosive consonants nor the glottal stop can form consonant clusters.
- When initial, the rhotic is trilled, when it appears in consonant clusters it is tapped.
- The consonant /ʝ/ has a good amount of allophony associated with it (each with requisite spelling changes in the Romanization):
- When it appears as a final, it moves to a velar realization, namely: [ɣ].
- As an initial and followed by /ɾ/ it undergoes fortition to [ɡɾ].
- However, if followed by /w/ it instead, becomes [ɡw].
- If a vowel would begin a syllable, it instead begins with [ʔ], which is unwritten.
- When /ɛ/ is in the final position of a syllable, it centralizes to a shcwa: [ə].
- If a glottal stop begins the second syllable in a two syllable compound, the consonant is written as an apostrophe.
- Stops that appear in the coda of a syllable are voiced, however the spelling isn't changed (the /ʔ/ → /q/ situation being an exception).
- The o-group's diphthong's two realizations are in free variation and depend on the speaker.
- Some speakers pronounce the i-group diphthong (ya) as [iː] rather than [ɪə̯]. The two are not conditioned variants and are in free variation.
Another allophonic variation occurs in two-syllable compound words (such as the language's name). Whenever an implosive appears second in one of these two-syllable compounds, it laxes the vowel in the first position of the compound if it is a plain vowel and de-lengthens a long vowel to its plain equivalent.
Grammar
Vingdagese has a rather simple grammar in which there are few exceptions to rules, and essentially no morphology. Instead, it uses particles, and noun- and verb- compounding to express more complex structures. Possession is somewhat of an exception in that there are two methods to express it, with one only being used if the animacy hierarchy must be violated. Vingdagese, as the previous statement would imply, also has a hierarchy with regard to animacy. This means an obviative particle exists to de-rank nouns, as well as a direct-inverse structure to its clauses.
Another feature of the language is the use of a small system of noun classifiers when a number of demonstrative is used with a noun. These also come into play as a form of noun replacement when a noun has already been referred to an exchange. This enables a sort of verbal shorthand to be used.
Pronouns
| Number | |||||
|---|---|---|---|---|---|
| Person | Singular | Dual | Paucal | Plural | |
| First | Incl | cwơc I, me |
twon you and me |
mmưng you few and me |
vơ you (pl) and me |
| Excl | cwơc-ay we two |
qodh we (few) | |||
| Second | regh you |
ḍú you (few, two) |
dhi you (pl) | ||
| Third | dhưn he; she; they (sg) |
dhregh they (few, pl) | |||
Classifiers
Classifiers in Vingdagese are used whenever a number is used to refer to the quantity of an object. They can also be used as a kind of pronoun when referring to an object or idea that has been previously referenced in the context of the current conversation.
Each classifier is used as a suffix to the noun to which it refers. In some cases, this will trigger vowel laxing/shortening since a number of classifiers contain an implossive consonant. This system is much smaller than some East Asian languages' classifier (measure word) systems, and is more in line in number of items with European noun class systems.
All humans and anthropomorphized animals belong to the human class. Using a non-human classifier in reference to a person is extreme sign of disrespect or possibly disregard for that person entirely (depending on what class is chosen). All non-antrhopomorphized animals fall into the animate class. However, this class is also for things that routinely move of their own accord including rain, lakes, fire, fields of tall grass, etc. Non-animate nouns can be referred to as part of that class if something about them makes movement important. A thrown ball, for instance might be referred to that way at times. The tall class is fairly restricted. This class is for any object that is much taller or longer than it is wide. Objects such as trees, rivers, poles, mountains, deep cracks and other similar geographic features all fall into this category. However, there aren't many cases where this category is extended. The "round" classifier is perhaps the most open. Any object that isn't considered to be tall, shapeless, especially flat or alive can end up in this category. As such, the round classifier is the one most common to be generalized similarly to the Chinese classifier 個 (gè). Next is the flat classifier. This one is used mainly for things like tables, boards, plains, the surface of a calm lake, etc. It too is a rather restrictive class. Amorphous is the classifier that is applied to pools of water like puddles, types of liquids (esp. foods), bodily fluids, etc. And last but not least, is the category associated with every other noun that does not have a physical existence per se, this class is for ideas, thoughts, emotions, states of being, etc.
| Physical | Abstract | |||||
|---|---|---|---|---|---|---|
| Human | Animate | Inanimate | ||||
| Tall/ Long |
Round | Flat | Amorphous | |||
-ngi |
-qo |
-ġi |
-ġo |
-ḍi |
-ḅa |
-ḅo |
- Ḅo's phonogram, when used as a clasifier, is not the traditional symbol with an open bottom, but instead a version of it using a closed rectangle instead. This may have become common practice to make it less similar to the long-object classifier and/or animate classifier.
- As more nouns are coined, it may become necessary to revise the names/uses of these categories somewhat. At present, it seems like an okay system that should be able to handle itself. Other terms for the overarching categories may eventually be coined so that perhaps a generic "inanimate" classifier can be used. However, I don't believe that would be useful as it should simply be sorted into one of the sub-divisions.
Animacy Hierarchy
Related to classifiers, and the above chart, is the animacy hierarchy. Things can be "owned" only by those things farther left on the chart than them. So, what this means is that a thought (abstract) can't own anything through use of the poss suffix, however, anything else classed on the table can own it. What this means is that should something flat need to own something round an alternate construction would need to be used to indicate that. Typically this construction will use a verb indicating possession along with the inverse marker (ḍưm ![]() ).
).
The above hierarchy is followed also for transitive verbs. It is always assumed that an object/person higher on the hierarchy will perform the action on the object lower on the hierarchy. This is considered the direct construction. However, if the opposite is true, then the inverse marker must be appended to the verb to indicate that the hierarchy is working in reverse and the lower object is indeed the one performing the action. Should two participants in a transitive construction belong to the same rank on the hierarchy, then the object to which the action is occurring is "de-ranked" on the hierarchy by appending the obviative particle phonogram, namely, ti (![]() ).
).
As subcategories of the "human" rank in the hierarchy, the pronouns are ranked second, first, third. Additionally, a singular object always ranks higher than a plural object.
Given the above, the full hierarchy is as follows:
| Human | Animate | Inanimate | Abstract | |||||
|---|---|---|---|---|---|---|---|---|
| Second | First | Third | Long | Round | Flat | Amorphous | ||
| Singular | Plural |
|---|
Aspects
Vingdagese is devoid of marked tenses, and instead relies on its aspectual system to convey a good portion of meaning of the verb. Of course, there are periphrasitc ways to convey things like the past tense by stating "yesterday" or the like, but aspects are the primary system. Almost all aspects are conveyed through the use of an aspectual suffix as described in the below table (some of which, like the classifiers, will add requisite laxing/shortening to the previous vowel in the root due to the implosives). There is, however, one "suffix" that results in the complete reduplication of the verb root.
In addition to the aspects described below in the table, a verb bereft of any of the aspectual markers is considered to be in a type of general gnomic aspect; that is, stating the nature of things, or without any sense of time or the relation of the action to the passage of time or manner.
Each aspect exists in opposition to another aspect, with the exception of the Frequentative. These dualities usually focus on a particular quality that unites them, but also divides their usages. They are laid out along with their "opposite" in the table below.
| Perfective |
|
Imperfective | -ġa | ||||
|---|---|---|---|---|---|---|---|
| Action is completed (as expected). | Action is continuous. | ||||||
| Inchoative |
|
Cessative |
| ||||
| Action is about to start, or just started. | Action has just ended, or was interrupted. | ||||||
| Progressive |
|
Momentane |
| ||||
| Action is on-going (toward completion). | Action occurs once, over a negligible time. | ||||||
| Frequentative |
| ||||||
| Action occurs many times; often. |
There is also an emphatic particle that is related to, but not mutually exclusive with, any of the above aspects that marks explicit and often forceful intention of the action that it modifies. This marker is ḅi (![]() ).
).
Perfective vs. Imperfective
The duality here is whether the action is completed (or even complete-able in the first place). An action in the perfective aspect is one with a natural end-point and has reached that logical endpoint. On the other hand, actions in the imperfective express either that there is no natural endpoint for that action, or that such an endpoint is not going to be reached. Actions such as "going for a walk" are actions that are imperfective as there is no normal endpoint until the person stops walking.
Inchoative vs. Cessative
Here the central focus is on the beginning and end of an action. Where the perfective expresses an action that ended as expected, the Cessative is used most often when an action is stopped abrubtly, especially with actions that do have a natural endpoint that simply hasn't been reached due to interruption. Inchoative aspect is used to express the nature of "about to..." or "has just begun to..." No sense of premature beginning is implied, contrary to the other half of this pair.
Progressive vs. Momentane
This duality centers around the nature of the action's completion with relation to its endpoint. A progressive action is one in which the action moves more and more toward completion the longer it is performed. Painting (esp. a discrete object) is a good example of a time to use the progressive. However, the momentane aspect is used when the entirety of the action is its own completion. Striking a bell, or punching a wall would both be momentane, as the entirety of the action is accomplished before any sense of progress could be ascertained.
Frequentative
This is the only aspect without a partner, and the only aspect that is expressed as a changing suffix. Reduplication is used here to express the on-going nature of the event. Something in the frequentative happens over and over and over. Habitual actions could be described this way, as well as performing the same action continuously, one right after the next. This is distinguished from the progressive as no notable progress is made toward a foreseeable goal or endpoint. Hitting someone again and again and again could be frequentative; however, "hitting someone until they are unconscious," may be a better fit for the progressive aspect as there is a goal and natural endpoint of the action.
Examples
In the following, intf signifies an "intensifier" which makes what it modifies more impactful.
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
- Ḍúgh-ca
- / ɗuːʝ.ka
- ḍúgh-ca
- neg-intf
- tǫtǫ-ġa
- tõ.tõ.ɠa
- tǫ~redupl-ġa
- to speak~freq-imp
- cwơc
- kwɔɡ
- cwơc
- 1SG
- ni
- ni
- ni
- or
- prą-tre
- pɾã.tɾɛ
- prą-tre
- son-poss
- cwơc.
- kwɔɡ /
- cwơc
- 1SG
![]()
![]()
![]()
![]()
![]()
![]()
![]()
- Cwơc
- / kwɔɡ
- cwơc
- 1SG
- ém-ca
- eːm.ca
- ém-ca
- to see-intf
- vú
- vuː
- vú
- five
- pwơqo.
- pwɔ.qo /
- pwơ-qo
- wolf-clf.anim
Writing & Script
Each character written in Vưng-Ḍác Tǫ consists of two components. The first element is the Logogram and it serves to differentiate characters that mean different things, refer to different parts of speech or to give a clue to the meaning of the word. Here, logogram is used loosely and simply felt like a good word to describe the purpose of that portion of a character. A complete list of the possible logograms used in Vưng-Ḍác Tǫ is not feasible as there isn't a discreet number of them, and they have the most variation among them. Also, some of the logograms are indeed identical in appearance (if not function) to the second part of Vingdagese written characters. The second in each is a Phonogram. Phonograms do belong to a finite group, that describe a portion of the basic syllables possible in Vingdagese. Keep in mind that phonograms represent an older, simpler, version of the possible compliments of syllables. They do not include any consonant clusters, final consonants, non-cardinal vowels or diphthongs. All of that phonological information is conveyed in the combination of the Phonogram and Logogram portions toghether. Phonograms alone are not sufficient for proper pronunciation.
Phonograms
The primary function of phonograms in the written language of Vingdagese is to establish a general range of possible ways in which the character could be pronounced. At one time, the language was a syllabary and was written exclusively with these phonograms (though some of them have changed form since then). However, a vast array of homophones and ambiguity began to exist in the written language... especially as the spoken language changed to add more variety in the ways that syllables were constructed. As such, additional components were added to lower ambiguity in the usage of characters. From that point on, there were two parts to each character, and the relationship between written phonogram and spoken syllable have greatly diverged. This has primarily occurred with respect to the exact vowel used, initial clusters and in coda consonants. Now, though, it does serve as a useful tool to organize characters alphabetize and also to roughly group similar sounding characters together.
| Cardinal Consonant | ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Vowel | ’ | Ḅ | C | Ḍ | Dh | G̣ | T | M | N | Ng | P | R | J | V |
| A | ||||||||||||||
| I | ||||||||||||||
| O | ||||||||||||||
Characters
- —For a chart of characters in Vưng-Ḍác Tǫ including unique phonograms, see: Characters
Writing
For the most part, strokes in written Vingdagese are in a similar order as to what they would be in Chinese, or what is presumed to be the stroke order in written Tangut. However, there are some notable exceptions. One such exception is that of the "square" (three of which make up the phonogram ca). In Chinese, each square would be written with three strokes, starting with the left, then the top and right sides forming an L-like shape with an uptick on the tail and finishing it off with the bottom stroke. However, in Vingdagese, it is written with only two strokes (one for the left and bottom and the other for the top and rightmost sides, with the omission of any uptick on the rightmost stroke).
Another notable feature is the fact that many of the grammatical components of the language are written with a single phonogram instead of an entire character. In those situations, a middle dot is used to substitute what would have been the rest of the character and also to highlight that it isn't a full two-sided character. This dot is omitted in casual or quick writing, but is visually distinctive in a more formal hand.
Numbers
Numbers in Vingdagese can be written formally or informally. In the formal method, the phonogram is included in each character which increases the stroke count significantly. However, they can also be written in their "short" forms which correspond in number to the number of strokes that are in the glyph and include solely the base form of the logogram that appears in the formal version. It is far more common to see the numbers written in their short versions. However, this version also has some forms that are identical to certain phonograms, but are pronounced differently when used as a number. The following table shows the pronunciation, value, short and formal forms of each character. Also of note is that Vingdagese uses an octal counting system in which the numbers 1-7 are the only ones used, and the character for 8 is actually a shorthand for 10. Place value has been used with these numbers for a number of years now, instead of a more archaic system where it was more like Roman numerals and there were other glyphs that served for 64 (8²), 512 (8³), etc. In the following table, the first character shown below each number is the long form, and the second is the short form.
Numbers are also grouped differently than in the standard Western Base 10 system. In the Western world, numbers are grouped by every three zeroes (or in other words, by the thousand). However, by the Ving, they are instead grouped by every two zeroes, or by the hundred. This means that one thousand (1,000) is spoken about as ten-hundred (10·00), etc. However, should there be a single digit that would be placed in the next grouping as in ♦1·00·00, it would instead be written without the first separator as: 100·00.
(This also may make it a bit easier to identify in which base a number is being expressed, as the middle dot will be used often with octal notation and Base 10 numbers will still feature the comma.)
| One (1) | Two (2) | Three (3) | Four (4) | Five (5) | Six (6) | Seven (7) | Eight (10) | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| mơt | ay | dháng | ḅơ | vú | nnem | qơ | ḅegh | ||||||||
| Zero (0) | 100 | 10·00 | 100·00 | 10·00·00 | 100·00·00 | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| ring | cren | twé | praq | ġưc | mmit | ||||||
Examples
Below are a few examples of the number system in actual use, as well as a comparison of the long and short forms in the final part separated by a slash.
- 37 (Base 10) → 45 (Base 8) →

 →
→  /
/ 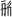

- In this example, the resultant character has some elements combined to reduce strokes and redundancy.
- 8,763 (Base 10) → 210·73 (Base 8) →





 /
/ 




- Use of the full characters gets quite unwieldy with large numbers. As such, one does not tend to see it.
- 4,097 (Base 10) → 100·01 (Base 8) →
 or
or
- In this example, the character cren is used to abbreviate a 1 with two 0s, since it had been used as 100 (or 64 in Base 10) in the older system. Now, these characters are only used as part of shorthand since they have been obsoleted by the advent of the current place value system.
Lexicon
- —For the current list of words in Vưng-Ḍác Tǫ, see: Lexicon.
Creator Comments
Vưng-Ḍác Tǫ is a language whose script is inspired by the real-world design of Tangut. This language is spoken by peoples living on the world of Carnassus. It too is believed to be an isolate, like the majority of the languages spoken on Carnassus.
This language began life with working with the Tangut script. Obviously, as this type of thing so often does, it inspired me to want to make a language to match. The obstacle, however, was how does one use such a complex stroke-heavy written script like Tangut in such a way that it begins to look unique, yet keeps the aesthetic? This is still a problem as the script and language develop, however it is not an insurmountable one. At present, I have ripped apart many Tangut characters into some base parts and components and have begun to stitch them back together again. Generally, this consists of the creation of two parts that are composed of chunks of the 3-part Tangut characters and then placed back together in such a way as to create a 2-part character. As is clear in the above chart, each character has a pretty distinct left- and right-half. As to what those will mean or how the script will ultimately function is still somewhat debatable. I am beginning to think that one aspect will have to do with the meaning in some way, while the other the sound, but this would take a great deal of coordination and logical organization of the constituent pieces. Maybe this will begin to develop as characters are chosen for disparate meanings and then later I can glue things together logically to make this system look more cohesive as it goes. Another key feature was the addition of some pieced together elements to make it look just a bit more "Chinese." One of the aspects of that aim is the "square" as well as the "hat" glyph form.